Linear Layer (Fully Connected Layer)
Gradient w.r.t weights
Gradient w.r.t bias
Gradient w.r.t input of the linear layer (to be passed backwards to earlier layers)
Convolutional Layer (1D Case)
For 1D convolution with input length , kernel length , output length :
Bias gradient: Given that
And so
Kernel gradient:
Input gradient:
Convolutional Layer (2D Case)
Here, I’m going to generalize to any dimensional convolution to 2D since that’s when its used. → which is a tensor, → which is a tensor, is the weight matricies we use for convolutions AKA kernels.
Where is the convolution operator. are spatial indicies, are spatial indicies of the kernel, is the input channel index, , is the output channel index. Basically, we shift around a kernel over an input and compute the sum of the element-wise multiplication of the kernel and the area in the input.
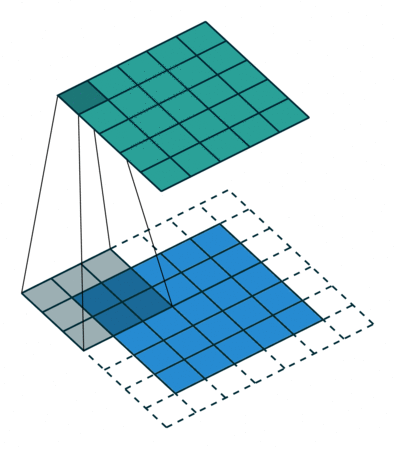
Gradient w.r.t kernel weights. We convolve the gradient over the input
Gradient w.r.t input. We convolve the gradient with a 180 degree horizontally flipped kernel
Gradient w.r.t bias. We sum the incoming gradient over that specific input channel
Scaled Dot-Product Attention
where:
- (queries)
- (keys)
- (values)
- (attention weights)
Backward:
This is the most complex. Given :
Gradient w.r.t. :
Gradient w.r.t. attention weights :
Gradient through softmax: Let (pre-softmax scores)
(This comes from the softmax Jacobian - messy but necessary)
Gradient w.r.t. and :
Finally, gradients w.r.t. weight matrices: