 Progressively blurs an image through Gaussian Blur and then utilizes difference of gaussians to determine points of interest
Progressively blurs an image through Gaussian Blur and then utilizes difference of gaussians to determine points of interest
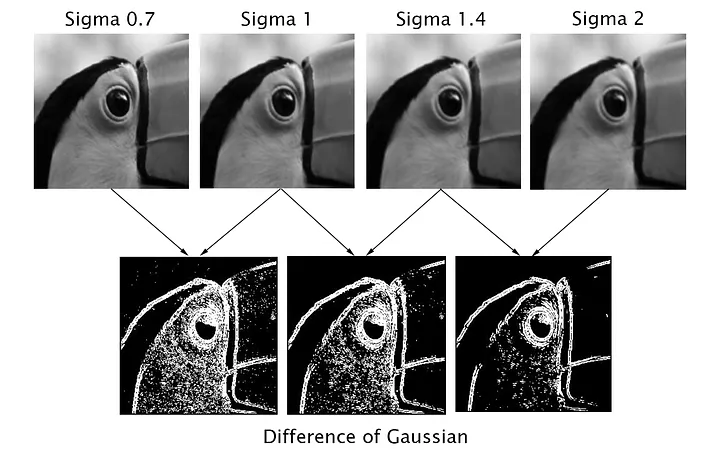
SIFT determines local maxima and minima. It does this by doing the following For each point
- Compare to 8 neighbors in the same scale
- Compare to 9 neighbors in the scale above
- Compare to 9 neighbors in the scale below
If it is the max or min, it is considered a keypoint candidate . where is the variance of the gaussian blur that we used at that specific layer. (A sub-pixel refinement scheme is done afterwards)
To Filter, theres a threshold you can set as the user.
We also want to describe our point further. We can do this with an Orientation Assignment.
Around the point, we organize the gradients of the pixels into a histogram (buckets of angles). The dominant orientation is added tot he keypoint
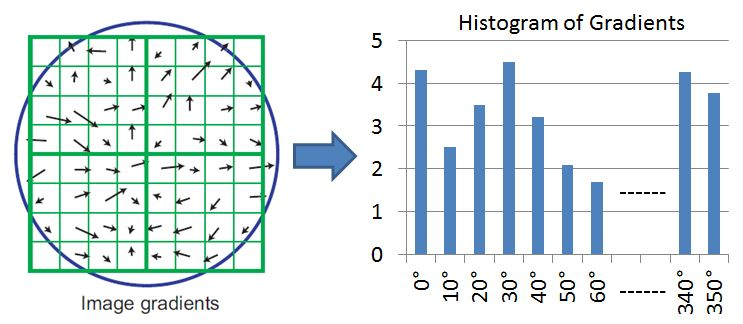 ^ finds the dominant orientation
v aligns on that dominant orientation and then constructs final feature vector
^ finds the dominant orientation
v aligns on that dominant orientation and then constructs final feature vector
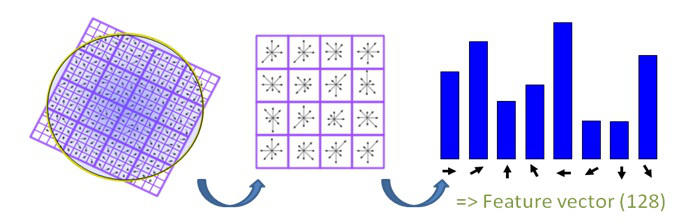
Final L2 Normalization step is done to make the descriptor invariant to linear illumination changes
Feature Matching
Can use Euclidean Distance (on the entire feature vector). Because they are linear, and normalized:
d(f₁, f₂)² = ||f₁||² + ||f₂||² - 2·f₁ᵀ·f₂
= 2 - 2·f₁ᵀ·f₂ (since ||f₁|| = ||f₂|| = 1)
For ORB, they use hamming distance, which is the number of differing bits of the vector
Optimizations
- Build a KD-tree on the descriptor space to search in O(logm)
- Approximate Nearest Neighbor