From Maximum A Posteriori we have the loss function
The gradient of which (which is used for Gauss-Newton Method is given by
Because the cost function is quadratic, our cost explodes when outliers cause major errors. To handle this, there are a series of wrappers that we can use to limit the effects of robot loss functions.
where is a scalar weight you can define, is some non-linear cost function (the wrapper).
Some possible cost functions are
is a specifiable parameter.
These cost functions don’t explode as much as the squared loss, and thus are more robust towards outliers. The downside is that we end up with slower convergence (but keep in mind that’s only if our data has very few outliers)

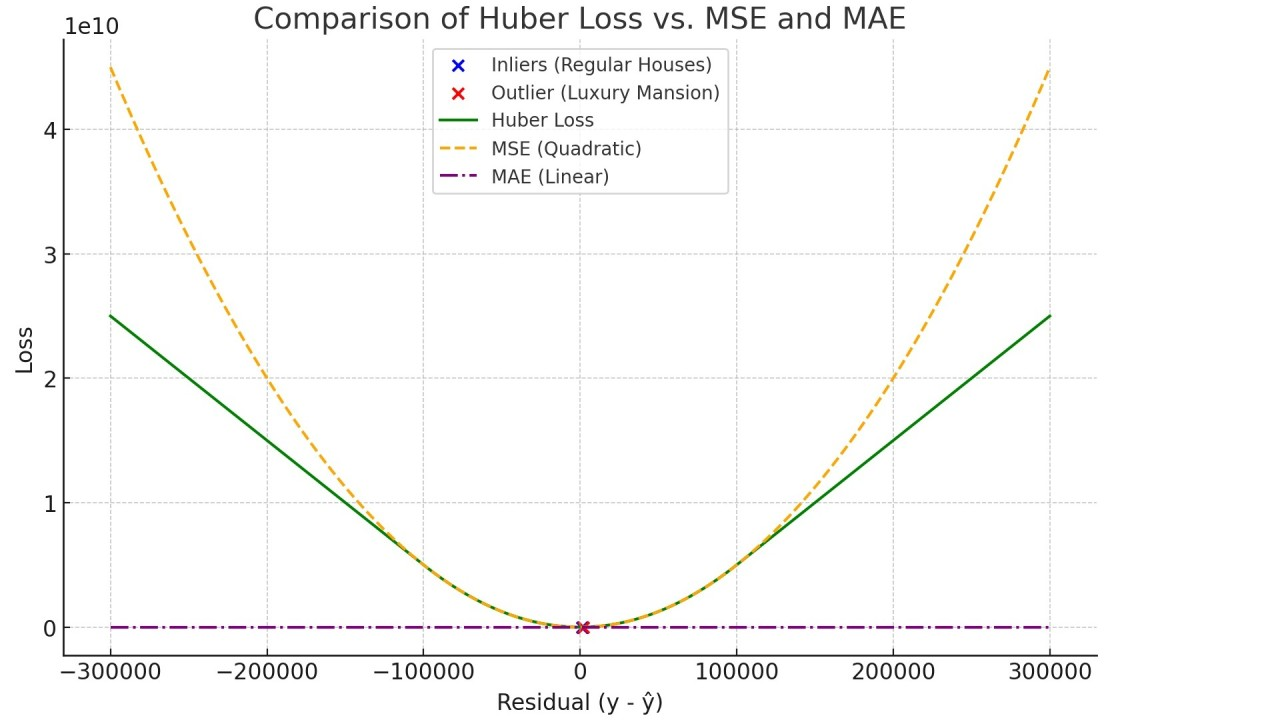
In the case of nice data, you don't need Robust Loss Functions like these.